ประโยชน์ของชีวสารสนเทศศาสตร์
|
โดยอาศัยข้อมูลพื้นฐานต่าง ๆ เช่น ลำดับดีเอ็นเอ ลำดับกรดอะมิโน โครงสร้างโปรตีน
เป็นต้น และใช้วิทยาการคอมพิวเตอร์ รวมถึงทักษะการเข้าถึงข้อมูลของนักวิจัย เพื่อลด
ระยะเวลาและงบประมาณในการวิจัย ลดความเสี่ยงต่อการใช้สัตว์ทดลองและการนำผลิต
ภัณฑ์ใหม่มาใช้กับมนุษย์ เช่น เมื่อนักวิจัยทราบลำดับเบสบนดีเอ็นเอบางส่วน สามารถนำ
เข้าไปค้นในฐานข้อมูลที่ให้ทราบว่าเป็นยีนอะไร เป็นยีนของสิ่งมีชีวิตชนิดไหน โดยใช้
โปรแกรมบลาสต์์เป็นเครื่องมือในการเปรียบเทียบลำดับเบสหรือลำดับกรดอะมิโนบนฐาน
ข้อมูล ในบางครั้งเมื่อทราบข้อมูลโครงสร้างของโปรตีน เราสามารถใช้โปรแกรม PROSITE
เพื่อเปรียบเทียบบางส่วนของโครงสร้างโปรตีนที่มีความคล้ายคลึงกัน เช่น การหาส่วนของ
โครงสร้างโปรตีนที่เป็นบริเวณเร่ง หรือการหาส่วนของโปรตีนที่สามารถจับกับดีเอ็นเอได้
ในทางการแพทย์และเภสัชกรรม สามารถใช้ชีวสารสนเทศศาสตร์เพื่อลดระยะเวลา
งบประมาณ และความเสี่ยงในทดสอบยาชนิดใหม่ต่อผู้ป่วยโรคต่าง ๆ เช่น มะเร็ง เบาหวาน
โรคหัวใจ เป็นต้น โดยศึกษาโรคในระดับยีนและออกแบบยาให้มีปฏิกิริยาเฉพาะต่อโรค
และสามารถทดลองนำยามาทำปฏิกิริยากับโปรตีนเป้าหมายในบริเวณเร่งของโปรตีนนั้น
หากสามารถจับกันได้อย่างจำเพาะเจาะจงจึงนำมาผลิตและทดลองใช้กับสัตว์ทดลองและ
คนต่อไป ตัวอย่างเช่น คณะวิทยาศาสตร์ มหาวิทยาลัยมหิดลร่วมกับศูนย์พันธุวิศวกรรม
แห่งชาติ ได้ทดสอบการจับตัวกันระหว่างยาต้านมาเลเรียกับบริเวณเร่งของเอนไซม์
dihydrofolate reductase-thymidylate synthase (DHFR-TS) จากเชื้อมาเลเรีย เป็นต้น
การผลิตยาในปัจจุบันอาศัยการออกแบบโดยการจำลองปฏิกิริยาการจับกันระหว่างยากับบาง
ส่วนของโครงสร้างของโปรตีนเป้าหมาย (molecular docking) โดยอาศัยโปรแกรม
คอมพิวเตอร์ เช่น SCULPT ร่วมกับการทดสอบยาหรือสารทั้งจากธรรมชาติิและการสังเคราะห์
ซ้ำ ๆ กันในภาวะเดียวกันโดยใช้เครื่องมืออัตโนมัติ (high-throughput screening) ทำให้
สามารถทดสอบจำนวนมาก ๆ กับโปรตีนเป้าหมายได้อย่างรวดเร็ว
 (ก) |
 (ข) |
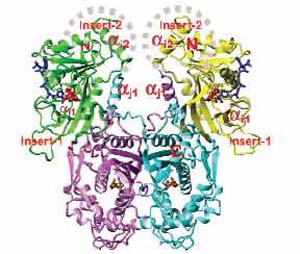
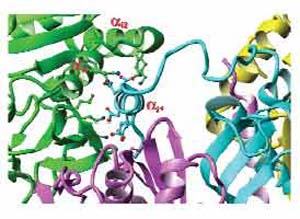
รูปที่
7.9 เอนไซม์ dihydrofolate reductase-thymidylate synthase
(DHFR-TS) จากเชื้อมาลาเรียชนิด Plasmodium falciparum
(ก) โครงสร้างสามมิติของเอนไซม์ DHFR-TS
(ข) บริเวณเกลียว ![]() j1
ซึ่งเป็นบริเวณยาต้านมาลาเรียมาจับเพื่อ
j1
ซึ่งเป็นบริเวณยาต้านมาลาเรียมาจับเพื่อ
ยับยั้งการทำงานของเอนไซม์
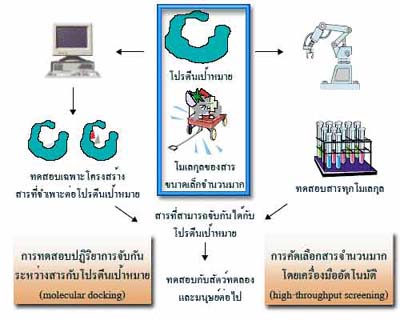
รูปที่
7.10 เทคนิคการผลิตยาในปัจจุบัน โดยวิธีทดสอบปฏิกิริยาการ
จับกันระหว่างสารกับโปรตีนเป้าหมาย
และการคัดเลือกสาร
จำนวนมากโดยเครื่องมืออัตโนมัติ
วิวัฒนาการและความหลากหลายทางชีวภาพ(biodiversity) โดยอิงข้อมูลลำดับเบส
บนสารพันธุกรรม หากสิ่งมีีชีวิตใดมีลำดับเบสที่คล้ายคลึงกันมากในบริเวณที่มีลำดับ
เบสสอดคล้องกัน (consensus sequence) ถือว่าอยู่ในกลุ่มเดียวกันหรือมีความสัมพันธ์
ด้านวิวัฒนาการใกล้ชิดกัน เป็นต้น
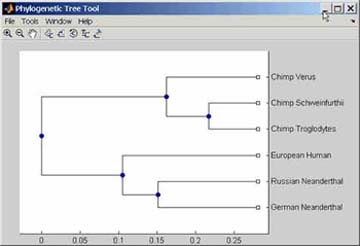
รูปที่
7.11 ตัวอย่างการใช้โปรแกรม Phylogenetic Tree เพื่อหา
ความสัมพันธ์ใกล้ชิดระหว่างมนุษย์และลิงชนิดต่าง
ๆ
ที่มา : (http://www.mathworks.com/access/helpdesk/help/toolbox/
bioinfo/ug/a1078325008b1.html)
|