| ความเป็นมาของชีวสารสนเทศศาสตร์
|
ยุคของชีวสารสนเทศศาสตร์เริ่มขึ้นมาจากผลของโครงการจีโนมมนุษย์
(human genome
project, HGP) ในปี ค.ศ. 1991 โดยมีสหรัฐอเมริกาเป็นแกนนำร่วมกับประเทศอังกฤษ
ฝรั่งเศส เยอรมัน ญี่ปุ่น และจีน เพื่อหาลำดับเบสที่เป็นส่วนประกอบในสายดีเอ็นเอทั้งหมด
ในมนุษย์ และจัดเก็บบนฐานข้อมูลคอมพิวเตอร์ขนาดใหญ่ของศูนย์ข้อมูลเทคโนโลยีชีวภาพ
แห่งชาติ (National Center for Biotechnology Information) ของสหรัฐอเมริกาและเปิด
เป็นเว็บไซต์ (website) ชื่อ http://www.ncbi.nlm.nih.gov/
เพื่อให้บริการการสืบค้นข้อ
มูลตลอดเวลาโดยไม่เสียค่าใช้จ่าย ซึ่งบรรจุข้อมูลลำดับเบสที่สมบูรณ์ของจีโนมมมุษย์
(ตีพิมพ์ในวารสาร Nature และ Science ในเดือนกุมภาพันธ์ 2001) และสิ่งมีชีวิตชนิดอื่นๆ
อีกมากมาย
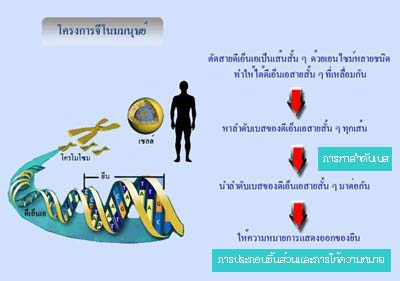
รูปที่
7.3 การหาลำดับเบส ประกอบชิ้นส่วนและการให้ความหมาย
การแสดงออกของยีนในโครงการจีโนมมนุษย์
ชีวสารสนเทศศาสตร์เกิดขึ้นโดยอาศัยวิทยาการคอมพิวเตอร์ที่ก้าวหน้าขึ้นอย่างรวดเร็ว
ในขณะนั้น ได้แก่ ความสามารถในการอ่านข้อมูลที่เพิ่มมากกว่า 100 กิกะไบต์ต่อวัน
ระบบจัดเก็บและประมวลผลข้อมูล รวมถึงระบบอินเตอร์์เน็ต (Internet) มีการพัฒนา
ให้ดีขึ้น ทำให้นักวิทยาศาสตร์ทั่วโลกสามารถค้นหาข้อมูลจีโนมได้อย่างรวดเร็ว
นอกจาก
นี้ยังมีการพัฒนาโปรแกรมประยุกต์์ต่าง ๆ เพื่อวิเคราะห์ข้อมูล สร้างแบบจำลองและแบบ
เสมือน (simulation and modeling) ทำให้สามารถทำนายปรากฏการณ์ทางชีววิทยาที่
อาจเกิดขึ้นจริงตามธรรมชาติ จึงช่วยลดงบประมาณและระยะเวลาในการศึกษาวิจัยในห้อง
ปฏิบัติการได้
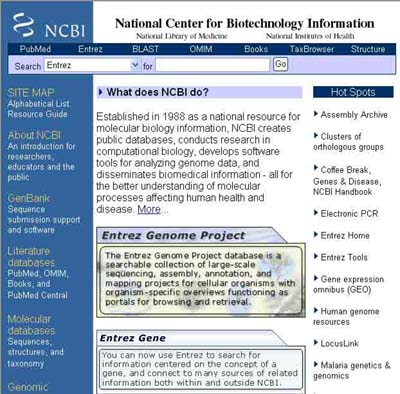
รูปที่
7.4 โฮมเพจของฐานข้อมูลจีโนมสิ่งมีชีวิตชนิดต่าง ๆ ของศูนย์
ข้อมูลเทคโนโลยีชีวภาพแห่งชาติ
(NCBI) ประเทศสหรัฐอเมริกา
ที่มา : (http://www.ncbi.nlm.nih.gov/)

รูปที่
7.5 วารสาร Science เล่มที่ 291 ฉบับที่ 5507 และ Nature
เล่มที่
409 ฉบับปี ค.ศ. 2001 ซึ่งตีพิมพ์ความสำเร็จของโครง
การจีโนมมนุษย์
ที่มา : (http://www.sciencemag.org/cgi/content/
full/291/5507/1304;
http://www.nature.com/genomics/
human/index.html)
คอมพิวเตอร์มีบทบาทสำคัญในงานชีวสารสนเทศศาสตร์ ดังนี้่
(1) งานชีวสารสนเทศศาสตร์เป็นงานที่ทำซ้ำ ๆ กันเหมือนเดิมเป็นล้าน ๆ ครั้ง
เช่น การ
เปรียบเทียบลำดับเบสใหม่กับลำดับเบสในฐานข้อมูล หรือการเปรียบเทียบกลุ่มของลำดับ
เบสเพื่อหาความสัมพันธ์ทางวิวัฒนาการ เป็นต้น งานลักษณะเช่นนี้ คอมพิวเตอร์สามารถ
วิเคราะห์และประมวลผลข้อมูลได้อย่างมีประสิทธิภาพ
(2) งานชีวสารสนเทศศาสตร์เป็นงานที่ต้องการอำนาจในการแก้ปัญหา (problem-solving
power) เช่น การทำนายลักษณะการพับของสายโพลิเพปไทด์ (polypeptide) จากลำดับ
กรดอะมิโน หรือการทำนายวิถีทางชีวเคมี (biochemical pathway) จากข้อมูลการแสดง
ออกของอาร์เอ็นเอ เป็นต้น แม้คอมพิวเตอร์จะมีบทบาทสำคัญในงานชีวสารสนเทศศาสตร์
์เป็นอย่างมากแต่การป้อนข้อมูลและรวบรวมข้อมูลต้นฉบับ (original data) โดยอาศัยผู้เชี่ยว
ชาญก็ยังจำเป็นอยู่เพื่อให้สามารถประมวลผลข้อมูลได้อย่างสมบูรณ์ครบถ้วน
|