ในตอนที่แล้วผู้เขียนได้อ้างถึง Whisper ซึ่งเป็นโมเดล AI ที่สามารถเสียงพูดจากบทสนทนาให้เป็นข้อความได้ในภาษาต่างๆ ในบทความนี้จะแสดงถึงความถูกต้องในการใช้งานจริงกับบทสนทนาภาษาอังกฤษที่พูดโดยคนไทย ซึ่งอาจจะมีความผิดเพี้ยนในแง่ของสำเนียง การใช้คำหรือประโยคภาษาอังกฤษ ทั้งนี้จะขอแปลจากบทคัดย่อชื่อ “Accuracy of auto transcription of in-depth interview among healthcare representatives from Thailand 2024” ซึ่งจะได้รับการนำเสนอที่งานประชุม APRU Global Health Conference 2024 ในช่วง 4-6 พฤศจิกายน 2567 ณ โรงพยาบาลจุฬาฯ
บทคัดย่อ:
ChatGPT ได้รับการตอบรับจากผู้ใช้อย่างแพร่หลายทั่วโลก เนื่องด้วยความสามารถในการโต้ตอบบทสนทนาได้เหมือนมนุษย์และความรู้อย่างมหาศาลจากโมเดลภาษาขนาดใหญ่ นอกจาก ChatGPT แล้วยังมีโมเดล AI ที่ชื่อว่า Whisper ซึ่งได้รับการ train ด้วยบทเสียงพูดความยาวกว่า 680,000 ชั่วโมงในภาษาต่างๆ Whisper ถูกนำมาใช้ในการแปลงจากเสียงพูดให้เป็นข้อความตัวหนังสือ Whisper มีความสามารถเหนือกว่าวิธีการแปลงเสียงเป็นคำพูดที่มีอยู่ในปัจจุบัน ในงานวิจัยนี้ Whisper API ถูกนำมาใช้ในการถอดบทสัมภาษณ์ภาษาอังกฤษจากบุคลากรผู้เป็นผู้ตัดสินใจในด้านการให้บริการทางการแพทย์ฉุกเฉินในไทย บทสัมภาษณ์นี้อยู่ภายใต้หัวข้อของ การสร้างความเข้มแข็งระบบสุขภาพไทย มีเหตุผลสามประการในการศึกษาความสามารถของ Whisper API ในบริบทนี้ อย่างแรกภาษาไทยถือว่าเป็นภาษาที่เป็นทรัพยากรที่ขาดแคลน (low resource language) ในการเรียนรู้ของโมเดล ดังนั้นหากมีคำภาษาไทยผสมอยู่ในบทสัมภาษณ์เช่น ชื่อไทย อาจทำให้ความถูกต้องในการถอดบทสนทนาน้อยลง เหตุผลที่สอง บทสนทนาดำเนินไปด้วยภาษาอังกฤษ ซึ่งภาษาอังกฤษไม่ใช่เป็นภาษาแม่หรือภาษาราชการของไทย ดังนั้นการออกเสียงภาษาอังกฤษโดยคนไทยอาจจะมีผลต่อความยากลำบากในการถอดบทสนทนา เหตุผลที่สาม เนื้อหาของการสัมภาษณ์นั้นเกี่ยวกับนโยบายด้านสุขภาพ ซึ่งถือว่าเป็นบริบทที่เฉพาะเจาะจง อาจจะมีคำศัพท์เฉพาะหรือศัพท์เทคนิคที่ไม่ได้ใช้กันทั่วไป ทั้งสามเหตุผลนี้อาจส่งผลถึงประสิทธิภาพของ Whisper ในงานวิจัยนี้ประสิทธิภาพของการถอดความด้วย Whisper ได้รับการศึกษาจากบทสัมภาษณ์จริงจากบุคลากร 6 ท่าน บทสัมภาษณ์มีความยาวรวมประมาณ 4 ชั่วโมง 45 นาที การถอดบทสัมภาษณ์ได้เป็นข้อความมากกว่า 45 หน้า ความผิดพลาดในการถอดบทสัมภาษณ์มีด้วยกัน 4 หมวดได้แก่ คำที่ได้ยินมาผิดพลาด คำที่หายไป คำที่เพิ่มขึ้นมา และคำที่สะกดผิด จากผลการศึกษา พบว่าความผิดพลาดโดยรวมมีเพียง 1.6 เปอร์เซ็นต์ ดังนั้น การวิจัยนี้ได้แสดงให้เห็นว่า Whisper สามารถใช้ในการถอดบทสนทนาในบริบทดังกล่าวและช่วยประหยัดเวลาให้กับผู้วิจัยอย่างมาก เนื่องจากการถอดสัมภาษณ์เป็นงานทั่วไปของนักวิจัยทั่วไป คณะผู้วิจัยถึงให้ความเห็นสนับสนุนการใช้ Whisper ในการดังกล่าวที่จะช่วยให้นักวิจัยทำงานได้อย่างมีประสิทธิภาพมากขึ้น
กระบวนการวิจัย
1. ดำเนินการสัมภาษณ์บุคลากร 4 ท่านทาง Zoom และ 2 ท่านแบบเข้าถึงตัว
2. บันทึกบทสัมภาษณ์เป็นไฟล์เสียง .M4A
3. ถอดบทสัมภาษณ์จากไฟล์เสียงด้วย Whisper API แล้วบันทึกเป็นไฟล์ Word
4. หลังจากตรวจสอบความถูกต้องของไฟล์ Word แล้ว ทำการจัดกลุ่มด้วย Nvivo-14
ผลลัพธ์การตรวจสอบความถูกต้อง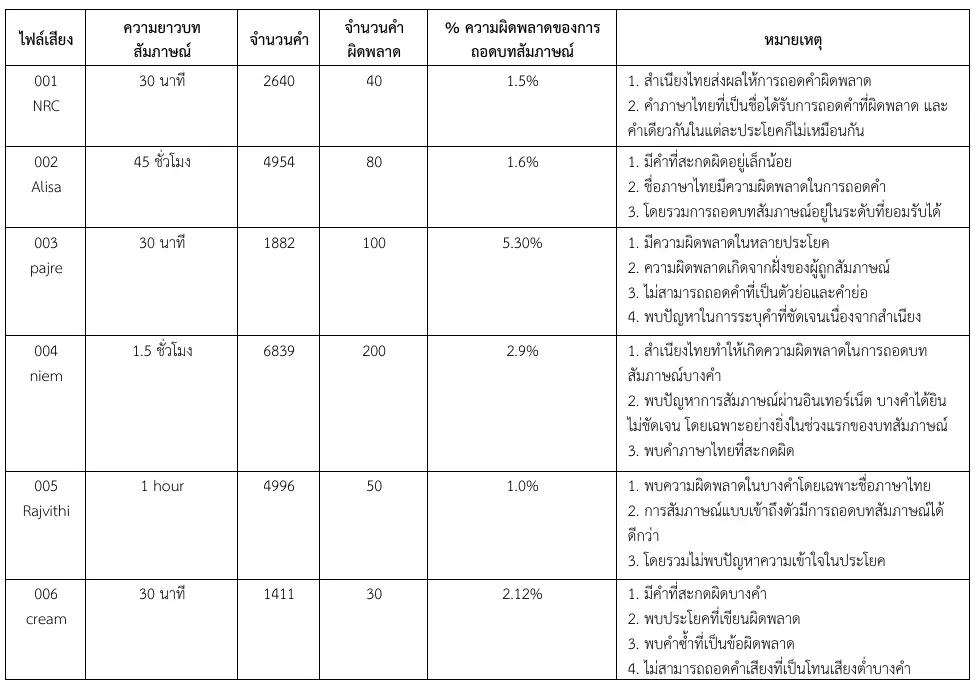
ตัวอย่างความผิดพลาดการถอดบทสัมภาษณ์
1. คำที่ได้ยินผิดพลาด
“effect”- “affect”; “contact”- “attack here”; “fraternal service”; “emergency care”- feminine care” ; “regulation”- “recreation”
2.คำที่หายไป
ตัวอย่างประโยคของคำที่หายไป “The policy to make the EMS is the……….Positive”.
3.คำซ้ำที่เพิ่มขึ้นมา
คำต่าง ๆ เช่น “The”, “a”, “okay”, “so”, “no”, “but how”, “preparedness”, “equipments” etc.
มีการถอดคำเป็นภาษาญี่ปุ่น เช่น
4. คำที่สะกดผิด
“Wichukorn suriyawongpaisal”- “Vishwakorn Siomavesan”; “NIEM”- “NIAMS”; “Ruamkatanyu”- “Ruam Katianu”, “Erawan center”- “Irawan”; “Poh Teck Tung”- “Phutektung”.
ผลการวิเคราะห์ความถูกต้อง
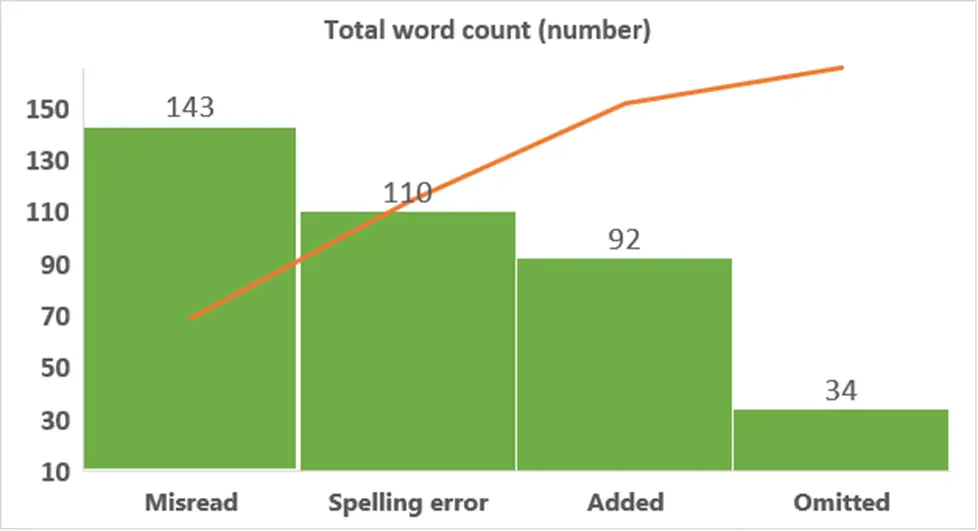
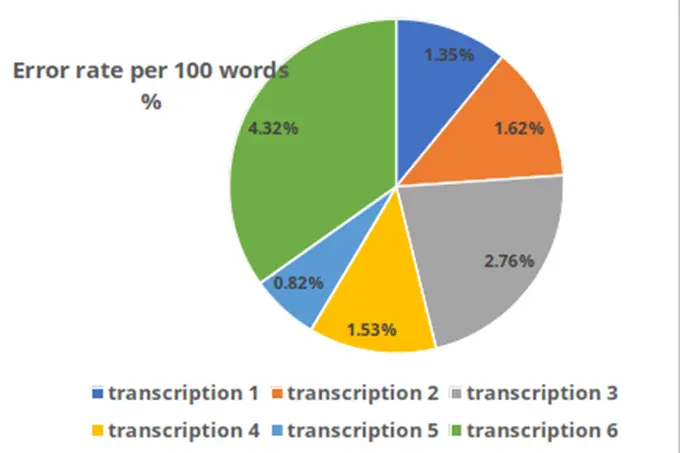
เนื้อหานี้มีประโยชน์กับท่านหรือไม่ โปรดให้คะแนน
 (1 votes, average: 4.00 out of 4)
(1 votes, average: 4.00 out of 4)