เมื่อพูดถึง ChatGPT ส่วนใหญ่ก็จะนึกถึงว่าเป็น chat bot หรือเป็นที่ไว้ค้นหาข้อมูลที่สามารถโต้ตอบกับผู้ใช้ได้เหมือนมนุษย์ และเข้าใจว่าเป็น AI ลักษณะหนึ่ง เบื้องหลังของ ChatGPT ก็คือโมเดลภาษาขนาดใหญ่ – Large Language Model (LLM) ที่ทำหน้าที่เหมือนสมองของมนุษย์คือเรียนรู้ จดจำและประมวลผลออกมาเป็นภาษามนุษย์ได้ บริษัทต่างๆด้าน AI ได้ทำการสร้าง LLM ที่มีความสามารถในแบบต่าง ๆ เช่น บริษัท OpenAI สร้างโมเดล GPT สำหรับ ChatGPT บริษัท Meta สร้างโมเดล LlAMA บริษัท Anthropic สร้างโมเดล Sonnet สำหรับ Claude.ai ส่วน Google ก็มีโมเดล Gemincและ xAI ของ Elon Mask สร้างโมเดล Grok เป็นต้น
องค์ประกอบของโมเดลภาษาขนาดใหญ่ คือโครงข่าย Neural Network ซึ่งเป็นโมเดลทางคณิตศาสตร์ที่มีการเชื่อมโยงกันอย่างซับซ้อนราวกับสมองมนุษย์ และมีลักษณะเฉพาะตัว ซึ่งมีชื่อว่า Transformer โดยสามารถเรียนรู้ความสำคัญของคำในประโยคและเชื่อมโยงกับคำอื่น ๆ ที่ใกล้เคียง โครงข่าย Neural Network สามารถเรียนรู้รูปแบบ (pattern) ที่ซับซ้อนโดยการปรับจูน weight หรือเรียกอีกชื่อหนึ่งว่า parameter ให้เข้ากับลักษณะของข้อมูลขาเข้าและผลลัพธ์ โดยมีจุดประสงค์ว่าเมื่อได้ parameter ที่เหมาะสมแล้ว โมเดลจะสามารถทำนายผลลัพธ์ได้อย่างถูกต้องเมื่อมีข้อมูลขาเข้าจากแหล่งใหม่ โดยทั่วไปยิ่งมีจำนวน parameter เยอะขึ้น โมเดลก็จะมีสามารถทำนายผลลัพธ์ได้แม่นยำมากขึ้น ตัวอย่างเช่น GPT version 3.5 มีจำนวน parameter มากถึง 175 พันล้าน ส่วน GPT version 4.0 มีถึง 1 ล้านล้าน parameter [1] ทั้งนี้การสร้างโมเดลขนาดใหญ่ต้องอาศัยต้นทุนในการทำให้โมเดลได้เรียนรู้ (training) อยู่ในหลักหลายล้านดอลลาห์ และต้องอาศัย Data Center ขนาดใหญ่ นอกจากนี้การได้มาซึ่งผลลัพธ์ระหว่างการใช้งาน (เรียกว่า Inference) ต้องสิ้นเปลืองพลังงานมาก
ในบางกรณี ผู้ใช้งานอาจจะไม่ได้ต้องความรู้ในหลากหลายสาขา แบบที่โมเดลภาษาขนาดใหญ่เรียนรู้มา แต่ต้องการคำตอบในสาขาวิชาย่อย ๆ หรือเฉพาะทาง เพื่อนำไปใช้ประโยชน์ได้บ้าง การใช้งานในลักษณะนี้สามารถตอบโจทย์ได้ด้วยโมเดลภาษาขนาดเล็ก – Small Language Model (SLM) ซึ่งโดยทั่วไปจะหมายถึง โมเดลภาษาที่มีจำนวนพารามิเตอร์น้อยกว่า จำนวน parameter ของโมเดลภาษาขนาดเล็กไม่ได้ถูกระบุอย่างชัดเจนว่าต้องไม่เกินเท่าไหร่ และอาจเปลี่ยนแปลงได้ตามเทคโนโลยีที่ก้าวหน้าขึ้น ในขณะนี้มีการยอมรับกันว่า SLM จะมีจำนวน parameter อยู่ที่ประมาณหลักหลายร้อยล้าน หรือพันล้านต้น ๆ โดยทั่วไปSLM มีลักษณะดังต่อไปนี้ [2]
- ประสิทธิภาพ – SLM ใช้ทรัพยากรในการเรียนรู้และการประมวลผลน้อยกว่า LLM ทำให้สิ้นเปลืองพลังงานน้อยกว่าซึ่งเหมาะสำหรับการใช้งานบนอุปกรณ์ที่มีกำลังไฟฟ้าจำกัดที่ต้องใช้แบตเตอรี่ เช่น โทรศัพท์มือถือ แทปเบล็ต หรืออุปกรณ์ IoT
- ความสามารถในการเข้าถึง (accessibility) – SLM ไม่จำเป็นต้องใช้ Data Center ในกระบวนการเรียนรู้ และการใช้งานก็ไม่จำเป็นต้องอาศัย cloud เหมือนกับ LLM ผู้ใช้งานสามารถใช้โมเดลบนเครื่องของตนเองโดยไม่จำเป็นต้องเชื่อมต่ออินเทอร์เน็ต ดังนั้น SLM จึงเหมาะสำหรับลักษณะงานที่ต้องการความเป็นส่วนตัวหรือความปลอดภัยสูงอีกด้วย
- ความสามารถในการปรับแต่ง (customization) – SLM สามารถเรียนรู้ในสาขาวิชาเฉพาะทางได้รวดเร็ว จึงสามารถปรับจูนให้เข้ากับงานเฉพาะทาง เช่น การให้บริการลูกค้า การให้บริการด้านสุขภาพ การให้บริการด้านการศึกษา เป็นต้น
- ให้ผลลัพธ์ที่รวดเร็ว – การประมวลผลลัพธ์ของ SLM ทำได้รวดเร็วกว่า จึงมีการตอบสนองที่ว่องไวกว่า ดังนั้นจะเหมาะกับแอพพลิเคชันแบบ real-time เช่น การแปลภาษา การสนทนาแบบโต้ตอบ การช่วยในการตัดสินใจแบบฉับไว
ตารางการเปรียบเทียบระหว่าง SLM กับ LLM [3]
หัวข้อ | SLM | LLM |
จำนวน parameter | สองถึงสามล้านถึงร้อยล้าน (และพันล้านต้น ๆ) | มากกว่าพันล้าน |
ทรัพยากรในการใช้งาน | เหมาะกับอุปกรณ์ที่มีทรัพยากรจำกัด | ต้องการทรัพยากรมากกว่า |
ความยากง่ายในการติดตั้งโมเดล | สามารถทำได้บนอุปกรณ์ขนาดเล็ก | มีความท้าทายเนื่องจากใช้ทรัพยากรมากกว่า |
ความเร็วในการเรียนรู้และให้ผลลัพธ์ | เร็วกว่าและมีประสิทธิภาพมากกว่า | ทำได้ช้ากว่า อาศัยการประมวลผลนานกว่า |
ประสิทธิภาพของโมเดล | สามารถแข่งขันกับโมเดลขนาดใหญ่กว่าได้ แต่อาจจะสู้ไม่ได้ในงานบางอย่าง | ประสิทธิภาพสูงกว่าด้วยโมเดลที่ทันสมัย |
ความต้องการด้านพื้นที่เก็บข้อมูล | 40-60% ของ LLM | ต้องการพื้นที่เก็บปริมาณมาก |
การใช้งานของโมเดล | อยู่บนอุปกรณ์ขนาดเล็ก | อยู่บนอุปกรณ์ที่มีทรัพยากรมากหรืออาศัย cloud |
ตัวอย่างของ SLM – Phi-2
Phi-2 เป็น SLM ที่ได้รับการพัฒนาโดยบริษัท Microsoft โดยมีจุดเด่นในเรื่องของการใช้เหตุผล (reasoning) และความสามารถความเข้าใจด้านภาษา (language understanding) Phi-2 มีจำนวน parameter ประมาณ 2,700 ล้าน ซึ่งยังถือได้ว่ามีขนาดเล็ก อย่างไรก็ตาม Phi-2 มีประสิทธิภาพเทียบเท่าหรือสูงกว่าโมเดลที่มีขนาดใหญ่กว่า ถึง 25 เท่า เช่น Mistral หรือ Llama-2 หรือ Gemini Nano 2
เป็นที่ทราบกันดีในวงการ AI ว่า ประสิทธิภาพของโมเดลขึ้นอยู่กับคุณภาพและความถูกต้องของข้อมูลที่ใช้ในการ train ด้วยเช่นกัน ทางทีมที่พัฒนา Phi-2 ได้อาศัยข้อมูลที่มีคุณภาพระดับหนังสือตำราเรียน โดยอ้างงานวิจัยที่ชื่อว่า “Textbooks Are All You Need.” ข้อมูลที่ใช้ train โมเดล Phi-2 มาจากหลายแหล่งตั้งแต่ข้อมูลสังเคราะห์ที่สร้างขึ้นมาเพื่อให้โมเดลมีความสามารถในการใช้เหตุผล ข้อมูลความรู้ทั่วไปในสาขาต่าง ๆ ได้แก่ สาขาวิทยาศาสตร์ กิจกรรมในชีวิตประจำวัน ทฤษฎีการทำงานของสมอง เป็นต้น ทั้งนี้ข้อมูลดังกล่าวต้องผ่านการกลั่นกรองโดยผู้เชี่ยวชาญโดยจะเน้นคุณค่าด้านการศึกษาและคุณภาพของเนื้อหา
การใช้งาน SLM
ในขณะที่การใช้งาน LLM ส่วนใหญ่ มีหน้าเว็บไซต์ที่รองรับอยู่แล้ว การใช้งาน SLM จำเป็นจะต้องมีการ Download โมเดลด้วยผู้ใช้งานเอง ในที่นี้จะยกตัวอย่างการใช้โปรแกรมที่ชื่อว่า Ollama ซึ่งเป็นโปรแกรมที่ใช้งานได้ฟรีและสามารถติดตั้งได้บนเครื่อง PC หรือโน้ตบุ๊คทั่วไป สามารถทำงานได้บนระบบปฏิบัติการ Windows, Linux และ macOS โปรแกรม Ollama ทำหน้าที่เป็น platform ในการใช้งานหรือปรับจูน SLM หรือ LLM
กระบวนการติดตั้งเริ่มจากการเข้าไป Download โปรแกรมจาก https://ollama.com จากนั้นให้ install ลงไปในเครื่อง
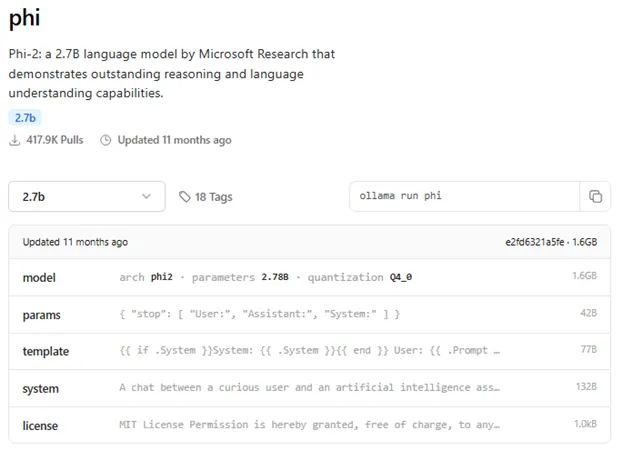
หากเราต้องการดูรายละเอียดของโมเดล ให้เข้าไป search บนช่อง Search models บนเว็บไซต์ ยกตัวอย่างสำหรับโมเดล Phi จะเห็นรายละเอียดดังรูปที่ 2
เราสามารถ Download โมเดล ได้จากคำสั่ง ollama pull ตามด้วยชื่อโมเดล เช่น
หลังจากนั้น เราสามารถเริ่มใช้งานได้ด้วยคำสั่ง ollama run ตามด้วยชื่อโมเดล ดังตัวอย่างด้านล่าง
เอกสารอ้างอิง
[1] “ChatGPT-4o vs GPT-4 vs GPT-3.5: What’s the Difference?” Online access: https://gettalkative.com/info/gpt-models-compared
[2] “Small Language Model: A Guide with Examples” DataCamp, Online access: https://www.datacamp.com/blog/small-language-models
[3] “What are Small Language Models (SLMs)?” Analytics Vidhya, Online access: https://www.analyticsvidhya.com/blog/2024/05/what-are-small-language-models-slms
[4] “Phi-2: The surprising power of small language models” Microsoft Blog, Online access: https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models
เนื้อหานี้มีประโยชน์กับท่านหรือไม่ โปรดให้คะแนน
 (No Ratings Yet)
(No Ratings Yet)